Note
Go to the end to download the full example code.
Global MetaONNX workflow
This example demonstrates how to deploy an ONNX model to Akida hardware using the onnx2akida toolkit. Starting from an ONNX model, we’ll show how to:
Convert and analyze compatibility with Akida hardware
Display compatibility reports
Create hybrid models combining Akida-compatible and ONNX operators
Generate inference models for deployment
We’ll use a MobileNetV4 model exported from HuggingFace as our example, though the workflow applies to any ONNX model.
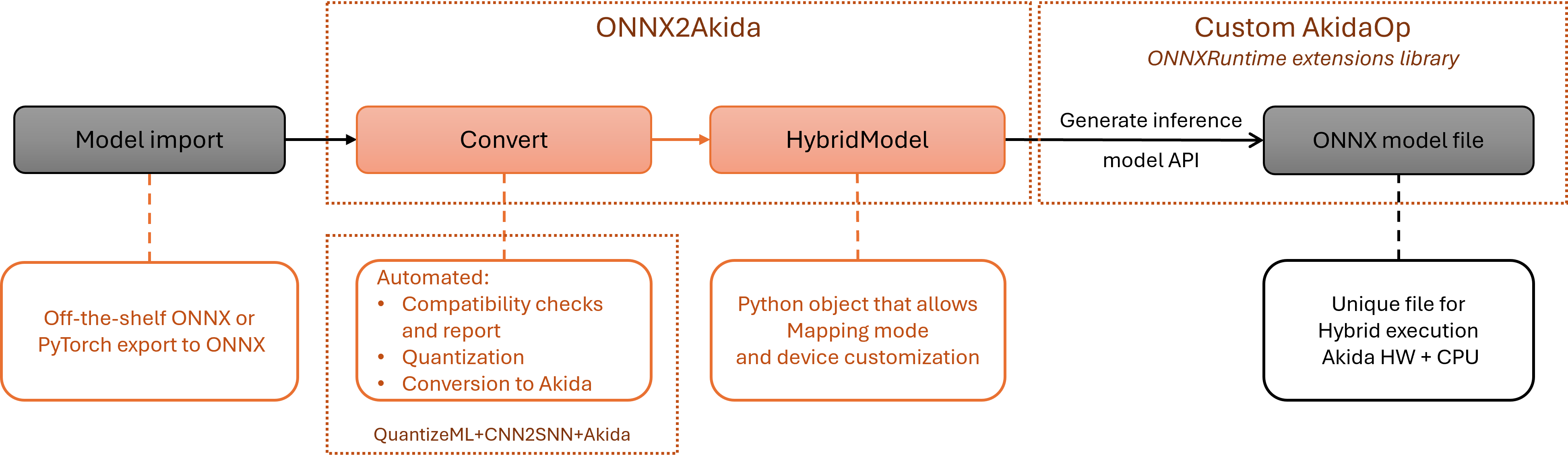
Global MetaONNX workflow
1. Export model to ONNX format
1.1. Export MobileNetV4 from HuggingFace
We’ll export a MobileNetV4 model from HuggingFace using the Optimum library. This demonstrates the typical workflow of obtaining an ONNX model for analysis.
You can also export models from other frameworks:
tf2onnx for TensorFlow
torch.onnx for PyTorch
import os
from optimum.exporters.onnx import main_export
model_dir = "mbv4"
main_export("timm/mobilenetv4_conv_small.e2400_r224_in1k", output=model_dir)
print(f"Model exported to {model_dir}/model.onnx")
Weight deduplication check in the ONNX export requires accelerate. Please install accelerate to run it.
Model exported to mbv4/model.onnx
1.2. Load the ONNX model
Load the exported ONNX model for analysis.
import onnx
model_path = os.path.join(model_dir, "model.onnx")
model = onnx.load(model_path)
print(f"\nLoaded ONNX model from {model_path}")
print(f"Model has {len(model.graph.node)} nodes.")
Loaded ONNX model from mbv4/model.onnx
Model has 89 nodes.
2. Convert to Akida
2.1. Convert and get compatibility information
The main entry point is the convert function, which analyzes the ONNX model and returns both a HybridModel and detailed compatibility information. The input_shape parameter specifies the expected input dimensions for the model. Models can be exported with a dynamic shape, but quantization and later Akida conversion and mapping need all input dimensions to be fixed.
from onnx2akida import convert
# Convert the model and analyze compatibility
# For MobileNetV4, the input shape is (channels, height, width)
print("\nAnalyzing model compatibility with Akida hardware...")
hybrid_model, compatibility_info = convert(model, input_shape=(3, 224, 224))
Analyzing model compatibility with Akida hardware...
Applied 1 of general pattern rewrite rules.
Applied 1 of general pattern rewrite rules.
Calibrating with 1/1.0 samples
[INFO] Searching sequences... done
Quantizing: 0%| | 0/1 [00:00<?, ?it/s]
Quantizing: 100%|██████████| 1/1 [00:00<00:00, 3.31it/s]
Quantizing: 100%|██████████| 1/1 [00:00<00:00, 3.31it/s]
/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /blocks/blocks.3/blocks.3.0/dw_start/conv/Conv because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/blocks/blocks.3/blocks.3.0/dw_start/conv/Conv (QuantizedDepthwise2DBiasedScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /blocks/blocks.4/blocks.4.0/conv/Conv because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/blocks/blocks.4/blocks.4.0/conv/Conv (QuantizedConv2DBiasedGlobalAvgPoolReLUScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /classifier/Gemm because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/classifier/Gemm (QuantizedDense1DFlattenBiased)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node node_Conv_1 because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
node_Conv_1 (QuantizedDepthwise2DReLUScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
Converting: 0%| | 0/5 [00:00<?, ?it/s]/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /conv_stem/Conv because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/conv_stem/Conv (QuantizedInputConv2DBiasedReLUScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
Converting: 60%|██████ | 3/5 [00:00<00:00, 29.80it/s]
Converting: 100%|██████████| 5/5 [00:00<00:00, 7.92it/s]
2.2. Display compatibility report
The obtained ModelCompatibilityInfo object contains detailed information about which nodes and subgraphs are compatible with Akida hardware. Use print_report to display a comprehensive analysis.
from onnx2akida import print_report
# Print detailed compatibility report
print_report(compatibility_info, hybrid_model)
Set of Incompatible op_types: ['Cast', 'Conv', 'Mul', 'Relu']
List of Incompatibilities:
❌ Node sequence: [node(op_type=Cast), node_1(op_type=Mul), /conv_stem/Conv(op_type=Conv), /bn1/act/Relu(op_type=Relu)]
• Stage: Mapping
• Faulty node: /conv_stem/Conv
• Reason: Cannot map layer '/conv_stem/Conv'. SameUpper padding is not yet supported.
[INFO]: Percentage of nodes compatible with akida: 95.6522 %
List of backends exchanges:
• CPU to Akida at layer /blocks/blocks.0/blocks.0.0/conv/Conv: 392.000 KB
• Akida to CPU at layer node_Conv_1: 36.750 KB
• CPU to Akida at layer /blocks/blocks.2/blocks.2.0/pw_proj/conv/Conv: 36.750 KB
• Akida to CPU at layer /blocks/blocks.3/blocks.3.0/dw_start/conv/Conv: 18.375 KB
• CPU to Akida at layer /blocks/blocks.3/blocks.3.0/pw_exp/conv/Conv: 18.375 KB
• Akida to CPU at layer /classifier/Gemm: 3.906 KB
The report shows:
The list of incompatibles operation types,
The list of incompatibilities indexed by node and by stage (quantization, conversion, mapping) indicating where an incompatibility was found and why,
Overall compatibility percentage,
The memory report for Akida to CPU transfers.
2.3. Understanding the HybridModel
The returned HybridModel object represents a model that can contain both:
Akida-compatible submodels (will be accelerated on Akida hardware)
Standard ONNX operators (will run on CPU via ONNXRuntime)
This hybrid approach allows partial acceleration even when not all operations are Akida-compatible.
Warning
Inference is not possible on the HybridModel directly. You have to explicitely generate an inference model as shown in the next section.
3. Generate inference model
3.1. Generate hybrid inference model with Akida device
To create a deployable inference model, you need an Akida device.
Important
A 2.0 FPGA device like available in Akida Cloud is used here for demonstration.
import akida
# Check for available Akida devices
assert len(devices := akida.devices()) > 0, "No device found, this example needs a 2.0 device."
print(f'Available devices: {[dev.desc for dev in devices]}')
Available devices: ['fpga-1743']
Inference happens on a device, so we need to map the hybrid model onto it. This can be done using HybridModel.map like shown below.
# Map on the device
fpga_device = devices[0]
try:
hybrid_model.map(fpga_device)
except RuntimeError as e:
print("Mapping failed:\n", e)
Mapping failed:
Failed to map Akida model at index 2 within 'akida_models'. Reason: Cannot map layer '/conv_head/Conv'. Not enough hardware component of type CNP1 available. 27 are needed but 21 are available..
Mapping the HybridModel onto the Akida device after conversion might fail: while some layers are supported by Akida hardware, they might not fit on device due to resource constraints. In such cases, you can try mapping on a larger virtual device - but that cannot be used for inference, it only serves for prototyping - or you can go back to model conversion and provide the device as a convert parameter.
hybrid_model, compatibility_info = convert(model, input_shape=(3, 224, 224), device=fpga_device)
Applied 1 of general pattern rewrite rules.
Applied 1 of general pattern rewrite rules.
Calibrating with 1/1.0 samples
[INFO] Searching sequences... done
Quantizing: 0%| | 0/1 [00:00<?, ?it/s]
Quantizing: 100%|██████████| 1/1 [00:00<00:00, 3.31it/s]
Quantizing: 100%|██████████| 1/1 [00:00<00:00, 3.30it/s]
/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /blocks/blocks.3/blocks.3.0/dw_start/conv/Conv because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/blocks/blocks.3/blocks.3.0/dw_start/conv/Conv (QuantizedDepthwise2DBiasedScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /blocks/blocks.4/blocks.4.0/conv/Conv because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/blocks/blocks.4/blocks.4.0/conv/Conv (QuantizedConv2DBiasedGlobalAvgPoolReLUScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /classifier/Gemm because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/classifier/Gemm (QuantizedDense1DFlattenBiased)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node node_Conv_1 because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
node_Conv_1 (QuantizedDepthwise2DReLUScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /blocks/blocks.3/blocks.3.0/dw_mid/conv/Conv because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/blocks/blocks.3/blocks.3.0/dw_mid/conv/Conv (QuantizedDepthwise2DBiasedReLUScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
Converting: 0%| | 0/7 [00:00<?, ?it/s]/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /conv_stem/Conv because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/conv_stem/Conv (QuantizedInputConv2DBiasedReLUScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
Converting: 71%|███████▏ | 5/7 [00:00<00:00, 25.45it/s]/usr/local/lib/python3.11/dist-packages/cnn2snn/quantizeml/onnx_conversion/model_generator.py:68: UserWarning: Conversion stops at node /conv_head/Conv because of a dequantizer. The end of the graph is ignored:
___________________________________________________
Node (type)
===================================================
/conv_head/Conv (QuantizedConv2DBiasedReLUScaled)
===================================================
.
This can be expected for model heads (e.g. softmax for classification) but could also mean that processing layers were not quantized.
warnings.warn(f"Conversion stops {stop_layer_msg} because of a dequantizer. "
Converting: 100%|██████████| 7/7 [00:00<00:00, 12.31it/s]
print_report(compatibility_info, hybrid_model)
Set of Incompatible op_types: ['Cast', 'Conv', 'Mul', 'Relu']
List of Incompatibilities:
❌ Node sequence: [node(op_type=Cast), node_1(op_type=Mul), /conv_stem/Conv(op_type=Conv), /bn1/act/Relu(op_type=Relu)]
• Stage: Mapping
• Faulty node: /conv_stem/Conv
• Reason: Cannot map layer '/conv_stem/Conv'. SameUpper padding is not yet supported.
❌ Node sequence: [/conv_head/Conv(op_type=Conv), /norm_head/act/Relu(op_type=Relu)]
• Stage: Mapping
• Faulty node: /conv_head/Conv
• Reason: Cannot map layer '/conv_head/Conv'. Not enough hardware component of type CNP1 available. 27 are needed but 24 are available.
[INFO]: Percentage of nodes compatible with akida: 93.4783 %
List of backends exchanges:
• CPU to Akida at layer /blocks/blocks.0/blocks.0.0/conv/Conv: 392.000 KB
• Akida to CPU at layer node_Conv_1: 36.750 KB
• CPU to Akida at layer /blocks/blocks.2/blocks.2.0/pw_proj/conv/Conv: 36.750 KB
• Akida to CPU at layer /blocks/blocks.3/blocks.3.0/dw_start/conv/Conv: 18.375 KB
• CPU to Akida at layer /blocks/blocks.3/blocks.3.0/pw_exp/conv/Conv: 18.375 KB
• Akida to CPU at layer /blocks/blocks.3/blocks.3.0/dw_mid/conv/Conv: 27.562 KB
• CPU to Akida at layer /blocks/blocks.3/blocks.3.0/pw_proj/conv/Conv: 27.562 KB
• Akida to CPU at layer /blocks/blocks.4/blocks.4.0/conv/Conv: 0.938 KB
• CPU to Akida at layer /classifier/Gemm: 1.250 KB
• Akida to CPU at layer /classifier/Gemm: 3.906 KB
The conversion algorithm knows the resource limitations, so it now avoids converting parts that do not fit on the device. That is why there are more incompatibilities (the node that was too big to fit on 6-node device will run on CPU), but operations that were mapped on the device can be accelerated by it.
# Generate the inference model
infer_model = hybrid_model.generate_inference_model()
3.2. Save the inference model
Once generated, the inference model can be saved for deployment.
inference_model_path = "model_inference.onnx"
onnx.save(infer_model, inference_model_path)
The inference model is a standard ONNX model that can be executed using ONNXRuntime. It’s graph
can be visualised with Netron and it will show AkidaOp nodes that are
custom wrappers for all Akida-accelerated submodels. It will also contain Transpose nodes
between ONNX and AkidaOp operators are automatically inserted to handle the different data layout
conventions (NCHW for ONNX, NHWC for Akida).
3.3. Perform an inference
The inference model can be executed using ONNXRuntime and the provided AkidaInferenceSession.
import numpy as np
from onnx2akida.inference import AkidaInferenceSession
# Generate random input samples with shape (batch_size, channels, height, width)
input_samples = np.random.randn(1, 3, 224, 224).astype(np.float32)
# Prepare and run inference
session = AkidaInferenceSession(inference_model_path)
input_name = session.get_inputs()[0].name
outputs = session.run(None, {input_name: input_samples})
print(f"Output shape: {outputs[0].shape}")
Output shape: (1, 1000)
5. Summary
The onnx2akida workflow enables you to:
Analyze any ONNX model for Akida compatibility
Identify which operations can be accelerated on Akida hardware
Generate hybrid models that combine Akida acceleration with standard ONNX operators
Deploy optimized inference models using ONNXRuntime
This approach maximizes hardware acceleration while maintaining full model functionality, even when only portions of the model are Akida-compatible.
Total running time of the script: (0 minutes 22.674 seconds)