Note
Go to the end to download the full example code.
PyTorch to Akida workflow
The Global Akida workflow guide describes the steps to prepare a model for Akida starting from a TensorFlow/Keras model. Here we will instead describe a workflow to go from a model trained in PyTorch.
Note
QuantizeML natively allows the quantization and fine-tuning of TensorFlow models. While it does not support PyTorch quantization natively, it allows to quantize float models stored in the Open Neural Network eXchange (ONNX) format. Export from PyTorch to ONNX is well supported, and so this provides a straightforward pathway to prepare your PyTorch model for Akida.
As a concrete example, we will prepare a PyTorch model on a simple classification task (MNIST). This model will then be exported to ONNX and quantized to 8-bit using QuantizeML. The quantized model is then converted to Akida, and performance evaluated to show that there has been no loss in accuracy.
Please refer to the Akida user guide for further information.
Note
pip install torch==2.0.1 torchvision
Warning
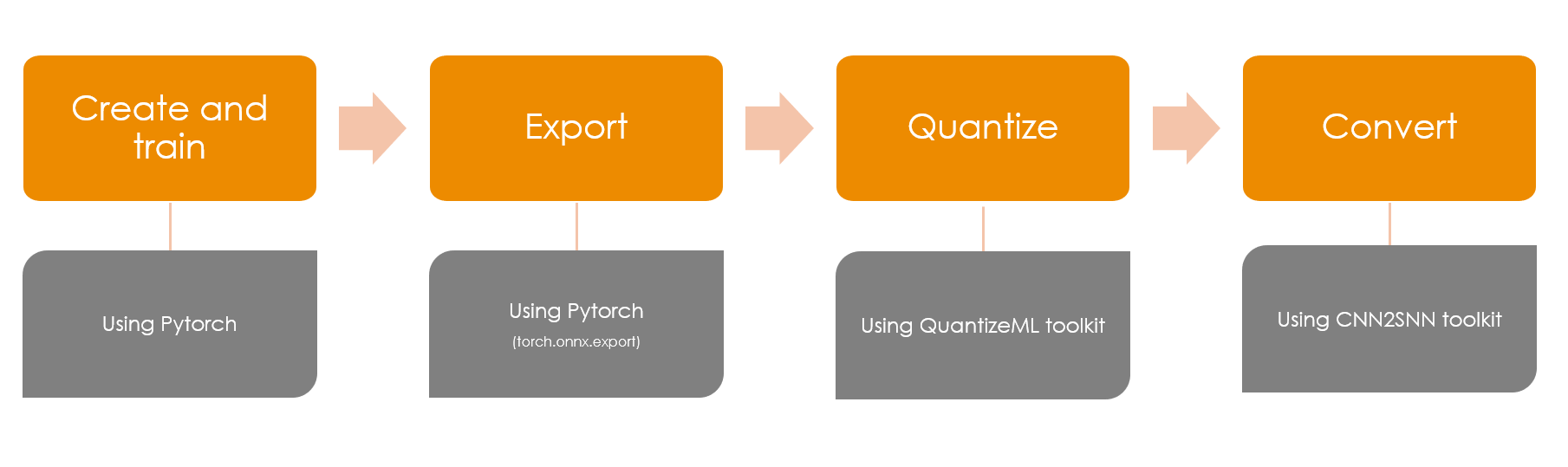
PyTorch Akida workflow
1. Create and train
1.1. Load and normalize MNIST dataset
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
batch_size = 128
def get_dataloader(train, batch_size, num_workers=2):
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(0.5, 0.5)])
dataset = torchvision.datasets.MNIST(root='datasets/mnist',
train=train,
download=True,
transform=transform)
return torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
shuffle=train,
num_workers=num_workers)
# Load MNIST dataset and normalize between [-1, 1]
trainloader = get_dataloader(train=True, batch_size=batch_size)
testloader = get_dataloader(train=False, batch_size=batch_size)
def imshow(img):
# Unnormalize
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(npimg.transpose((1, 2, 0)))
plt.show()
# Get some random training images
images, labels = next(iter(trainloader))
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Failed to download (trying next):
HTTP Error 403: Forbidden
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz to datasets/mnist/MNIST/raw/train-images-idx3-ubyte.gz
0%| | 0/9912422 [00:00<?, ?it/s]
1%| | 98304/9912422 [00:00<00:19, 501305.63it/s]
3%|▎ | 262144/9912422 [00:00<00:09, 976100.42it/s]
4%|▍ | 425984/9912422 [00:00<00:07, 1223494.24it/s]
8%|▊ | 819200/9912422 [00:00<00:04, 2162018.65it/s]
17%|█▋ | 1703936/9912422 [00:00<00:01, 4331309.66it/s]
26%|██▌ | 2555904/9912422 [00:00<00:01, 5146015.59it/s]
31%|███ | 3080192/9912422 [00:00<00:01, 5119110.58it/s]
59%|█████▉ | 5865472/9912422 [00:00<00:00, 11763144.12it/s]
72%|███████▏ | 7110656/9912422 [00:01<00:00, 9119243.40it/s]
93%|█████████▎| 9175040/9912422 [00:01<00:00, 11888056.80it/s]
100%|██████████| 9912422/9912422 [00:01<00:00, 7407160.65it/s]
Extracting datasets/mnist/MNIST/raw/train-images-idx3-ubyte.gz to datasets/mnist/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Failed to download (trying next):
HTTP Error 403: Forbidden
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-labels-idx1-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-labels-idx1-ubyte.gz to datasets/mnist/MNIST/raw/train-labels-idx1-ubyte.gz
0%| | 0/28881 [00:00<?, ?it/s]
100%|██████████| 28881/28881 [00:00<00:00, 300616.18it/s]
Extracting datasets/mnist/MNIST/raw/train-labels-idx1-ubyte.gz to datasets/mnist/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Failed to download (trying next):
HTTP Error 403: Forbidden
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz to datasets/mnist/MNIST/raw/t10k-images-idx3-ubyte.gz
0%| | 0/1648877 [00:00<?, ?it/s]
4%|▍ | 65536/1648877 [00:00<00:04, 340957.10it/s]
18%|█▊ | 294912/1648877 [00:00<00:01, 842736.61it/s]
46%|████▌ | 753664/1648877 [00:00<00:00, 1959057.20it/s]
95%|█████████▌| 1572864/1648877 [00:00<00:00, 3814320.43it/s]
100%|██████████| 1648877/1648877 [00:00<00:00, 2783752.79it/s]
Extracting datasets/mnist/MNIST/raw/t10k-images-idx3-ubyte.gz to datasets/mnist/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Failed to download (trying next):
HTTP Error 403: Forbidden
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz to datasets/mnist/MNIST/raw/t10k-labels-idx1-ubyte.gz
0%| | 0/4542 [00:00<?, ?it/s]
100%|██████████| 4542/4542 [00:00<00:00, 7205192.42it/s]
Extracting datasets/mnist/MNIST/raw/t10k-labels-idx1-ubyte.gz to datasets/mnist/MNIST/raw
# Show images and labels
imshow(torchvision.utils.make_grid(images, nrow=8))
print("Labels:\n", labels.reshape((-1, 8)))

Labels:
tensor([[3, 1, 8, 6, 7, 8, 6, 1],
[3, 1, 2, 6, 9, 2, 7, 1],
[6, 1, 5, 5, 2, 3, 4, 1],
[6, 9, 7, 9, 4, 3, 4, 3],
[9, 5, 3, 4, 5, 4, 8, 4],
[7, 9, 4, 3, 7, 2, 7, 4],
[9, 1, 6, 3, 6, 2, 5, 1],
[3, 0, 3, 5, 9, 3, 8, 7],
[2, 7, 9, 1, 9, 5, 2, 2],
[9, 2, 3, 7, 9, 2, 7, 4],
[3, 9, 8, 4, 3, 8, 8, 5],
[0, 0, 8, 0, 9, 4, 9, 4],
[1, 0, 8, 4, 9, 8, 6, 6],
[6, 4, 7, 4, 9, 0, 5, 4],
[8, 3, 5, 7, 3, 7, 1, 4],
[7, 8, 6, 4, 9, 3, 9, 2]])
1.2. Model definition
Note that at this stage, there is nothing specific to the Akida IP. The model constructed below uses the torch.nn.Sequential module to define a standard CNN.
model_torch = torch.nn.Sequential(torch.nn.Conv2d(1, 32, 5, padding=(2, 2)),
torch.nn.ReLU6(),
torch.nn.MaxPool2d(kernel_size=2),
torch.nn.Conv2d(32, 64, 3, stride=2),
torch.nn.ReLU(),
torch.nn.Dropout(0.25),
torch.nn.Flatten(),
torch.nn.Linear(2304, 512),
torch.nn.ReLU(),
torch.nn.Dropout(0.5),
torch.nn.Linear(512, 10))
print(model_torch)
Sequential(
(0): Conv2d(1, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU6()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2))
(4): ReLU()
(5): Dropout(p=0.25, inplace=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=2304, out_features=512, bias=True)
(8): ReLU()
(9): Dropout(p=0.5, inplace=False)
(10): Linear(in_features=512, out_features=10, bias=True)
)
1.3. Model training
# Define training rules
optimizer = torch.optim.Adam(model_torch.parameters(), lr=1e-4)
criterion = torch.nn.CrossEntropyLoss()
epochs = 10
# Loop over the dataset multiple times
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# Get the inputs and labels
inputs, labels = data
# Zero the parameter gradients
optimizer.zero_grad()
# Forward + Backward + Optimize
outputs = model_torch(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Print statistics
running_loss += loss.detach().item()
if (i + 1) % 100 == 0:
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
[1, 100] loss: 0.073
[1, 200] loss: 0.026
[1, 300] loss: 0.019
[1, 400] loss: 0.016
[2, 100] loss: 0.012
[2, 200] loss: 0.011
[2, 300] loss: 0.009
[2, 400] loss: 0.009
[3, 100] loss: 0.007
[3, 200] loss: 0.007
[3, 300] loss: 0.006
[3, 400] loss: 0.006
[4, 100] loss: 0.006
[4, 200] loss: 0.005
[4, 300] loss: 0.005
[4, 400] loss: 0.005
[5, 100] loss: 0.005
[5, 200] loss: 0.004
[5, 300] loss: 0.004
[5, 400] loss: 0.004
[6, 100] loss: 0.004
[6, 200] loss: 0.003
[6, 300] loss: 0.004
[6, 400] loss: 0.004
[7, 100] loss: 0.003
[7, 200] loss: 0.004
[7, 300] loss: 0.003
[7, 400] loss: 0.003
[8, 100] loss: 0.003
[8, 200] loss: 0.003
[8, 300] loss: 0.003
[8, 400] loss: 0.003
[9, 100] loss: 0.003
[9, 200] loss: 0.003
[9, 300] loss: 0.003
[9, 400] loss: 0.003
[10, 100] loss: 0.003
[10, 200] loss: 0.003
[10, 300] loss: 0.002
[10, 400] loss: 0.002
1.4. Model testing
Evaluate the model performance on the test set. It should achieve an accuracy over 98%.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
inputs, labels = data
# Calculate outputs by running images through the network
outputs = model_torch(inputs)
# The class with the highest score is the prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
assert correct / total >= 0.98
print(f'Test accuracy: {100 * correct // total} %')
Test accuracy: 98 %
2. Export
PyTorch models are not directly compatible with the QuantizeML quantization tool, it is therefore necessary to use an intermediate format. Like many other machine learning frameworks, PyTorch has tools to export modules in the ONNX format.
Therefore, the model is exported by the following code:
sample, _ = next(iter(trainloader))
torch.onnx.export(model_torch,
sample,
f="mnist_cnn.onnx",
input_names=["inputs"],
output_names=["outputs"],
dynamic_axes={'inputs': {0: 'batch_size'}, 'outputs': {0: 'batch_size'}})
============= Diagnostic Run torch.onnx.export version 2.0.1+cu118 =============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
Note
Find more information about how to export PyTorch models in ONNX at https://pytorch.org/docs/stable/onnx.html.
3. Quantize
An Akida accelerator processes integer activations and weights. Therefore, the floating point model must be quantized in preparation to run on an Akida accelerator.
The QuantizeML quantize()
function recognizes ModelProto objects
and can quantize them for Akida. The result is another ModelProto, compatible with the
CNN2SNN Toolkit.
Warning
ONNX and PyTorch offer their own quantization methods. You should not use those when preparing your model for Akida. Only the QuantizeML quantize() function can be used to generate a quantized model ready for conversion to Akida.
Note
For this simple model, using random samples for calibration is sufficient, as shown in the following steps.
import onnx
from quantizeml.models import quantize
# Read the exported ONNX model
model_onnx = onnx.load_model("mnist_cnn.onnx")
# Quantize
model_quantized = quantize(model_onnx, num_samples=128)
print(onnx.helper.printable_graph(model_quantized.graph))
/usr/local/lib/python3.11/dist-packages/quantizeml/models/quantize.py:461: UserWarning: Quantizing per-axis with random calibration samples is not accurate. Set QuantizationParams.per_tensor_activations=True when calibrating with random samples.
warnings.warn("Quantizing per-axis with random calibration samples is not accurate.\
Calibrating with 128/128.0 samples
graph torch_jit (
%inputs[FLOAT, batch_sizex1x28x28]
) initializers (
%quantize_scale[FLOAT, 1]
%quantize_zp[UINT8, 1]
%/0/Conv_Xpad[UINT8, 1]
%/0/Conv_Wi[INT8, 32x1x5x5]
%/0/Conv_B[INT32, 32]
%/0/Conv_pads[INT64, 8]
%/0/Conv_max_value[INT32, 1x32x1x1]
%/0/Conv_M[UINT8, 1x32x1x1]
%/0/Conv_S_out[FLOAT, 1x32x1x1]
%/3/Conv_Wi[INT8, 64x32x3x3]
%/3/Conv_B[INT32, 64]
%/3/Conv_pads[INT64, 8]
%/3/Conv_M[UINT8, 1x64x1x1]
%/3/Conv_S_out[FLOAT, 1x64x1x1]
%/7/Gemm_Wi[INT8, 512x2304]
%/7/Gemm_B[INT32, 512]
%/7/Gemm_M[UINT8, 1x512]
%/7/Gemm_S_out[FLOAT, 1x512]
%/10/Gemm_Wi[INT8, 10x512]
%/10/Gemm_B[INT32, 10]
%outputs/dequantize_scale[FLOAT, 10]
) {
%quantize = InputQuantizer[perm = [0, 1, 2, 3], scale = <Tensor>](%inputs, %quantize_scale, %quantize_zp)
%/2/MaxPool_output_0 = QuantizedInputConv2DBiasedMaxPoolReLUClippedScaled[pool_pads = [0, 0, 0, 0], pool_size = [2, 2], pool_strides = [2, 2], scale = <Tensor>, strides = [1, 1]](%quantize, %/0/Conv_Xpad, %/0/Conv_Wi, %/0/Conv_B, %/0/Conv_pads, %/0/Conv_max_value, %/0/Conv_M, %/0/Conv_S_out)
%/4/Relu_output_0 = QuantizedConv2DBiasedReLUScaled[scale = <Tensor>, strides = [2, 2]](%/2/MaxPool_output_0, %/3/Conv_Wi, %/3/Conv_B, %/3/Conv_pads, %/3/Conv_M, %/3/Conv_S_out)
%/8/Relu_output_0 = QuantizedDense1DFlattenBiasedReLUScaled[scale = <Scalar Tensor []>](%/4/Relu_output_0, %/7/Gemm_Wi, %/7/Gemm_B, %/7/Gemm_M, %/7/Gemm_S_out)
%outputs = QuantizedDense1DBiased[scale = <Tensor>](%/8/Relu_output_0, %/10/Gemm_Wi, %/10/Gemm_B)
%outputs/dequantize = Dequantizer(%outputs, %outputs/dequantize_scale)
return %outputs/dequantize
}
4. Convert
4.1 Convert to Akida model
The quantized model can now be converted to the native Akida format. The convert() function returns a model in Akida format ready for inference.
from cnn2snn import convert
model_akida = convert(model_quantized)
model_akida.summary()
Model Summary
______________________________________________
Input shape Output shape Sequences Layers
==============================================
[28, 28, 1] [1, 1, 10] 1 5
______________________________________________
________________________________________________________________
Layer (type) Output shape Kernel shape
=========== SW//0/Conv-outputs/dequantize (Software) ===========
/0/Conv (InputConv2D) [14, 14, 32] (5, 5, 1, 32)
________________________________________________________________
/3/Conv (Conv2D) [6, 6, 64] (3, 3, 32, 64)
________________________________________________________________
/7/Gemm (Dense1D) [1, 1, 512] (2304, 512)
________________________________________________________________
/10/Gemm (Dense1D) [1, 1, 10] (512, 10)
________________________________________________________________
outputs/dequantize (Dequantizer) [1, 1, 10] N/A
________________________________________________________________
4.2. Check performance
Native PyTorch data must be presented in a different format to perform the evaluation in Akida models. Specifically:
images must be numpy-raw, with an 8-bit unsigned integer data type and
the channel dimension must be in the last dimension.
# Read raw data and convert it into numpy
x_test = testloader.dataset.data.numpy()
y_test = testloader.dataset.targets.numpy()
# Add a channel dimension to the image sets as Akida expects 4-D inputs corresponding to
# (num_samples, width, height, channels). Note: MNIST is a grayscale dataset and is unusual
# in this respect - most image data already includes a channel dimension, and this step will
# not be necessary.
x_test = x_test[..., None]
y_test = y_test[..., None]
accuracy = model_akida.evaluate(x_test, y_test)
print('Test accuracy after conversion:', accuracy)
# For non-regression purposes
assert accuracy > 0.96
Test accuracy after conversion: 0.9854000210762024
4.3 Show predictions for a single image
Display one of the test images, such as the first image in the aforementioned dataset, to visualize the output of the model.
# Test a single example
sample_image = 0
image = x_test[sample_image]
outputs = model_akida.predict(image.reshape(1, 28, 28, 1))
plt.imshow(x_test[sample_image].reshape((28, 28)), cmap="Greys")
print('Input Label:', y_test[sample_image].item())
print('Prediction Label:', outputs.squeeze().argmax())

Input Label: 7
Prediction Label: 7
Total running time of the script: (2 minutes 48.806 seconds)